
Continuous Delivery is a foundational skill that your organisation needs to be good at if it is to remain responsive and ’lowercase a’ agile.
A full solution for continuous delivery tends to include (but isn’t limited to):
- The ability to create artefacts that we can release to production, across many products, teams, branches, environments and repositories.
- The ability to quickly validate an artefact as a candidate for release (through applying the testing triangle - unit, integration, acceptance, smoke and so on).
- The ability to release code to production without necessarily activating it for users (typically through feature flags, canary built and graduated rollouts).
- The ability to rapidly respond if a release candidate we later find to be problematic (again through canary builds, graduated rollouts, and by quickly rolling back software found to be problematic).
- The ability to audit or understand what code is where, what state that code is in, and why that code is where it is.
More concretely, a decent CI/CD solution will:
- Build your code
- Run the tests
- Deploy it to an environment
- Roll-back if there is an issue
Building an excellent build tool is no easy task, and because of the variety of use cases out there, you tend to find tools optimised for those use cases. They’ll be passable or useful in that niche and poor outside of it. Use-case variety and the complexity of the problem space is part of the reason why container-based builds have taken off. Where previously I’d have precious build agent boxes sitting somewhere that I’d need to feed and water and love and sell my children to, now I can have a dumb build box that knows about nothing. The build box just grabs a container off the internet (or I make a custom container) to fill my needs.
Github Actions
Github Actions is one such container based build offering, though at first they don’t tell you that!
The highest order concept in Actions is the Workflow. A workflow consists of several jobs, and each job can have several steps. Here’s an example we’ll become a bit more familiar with later:
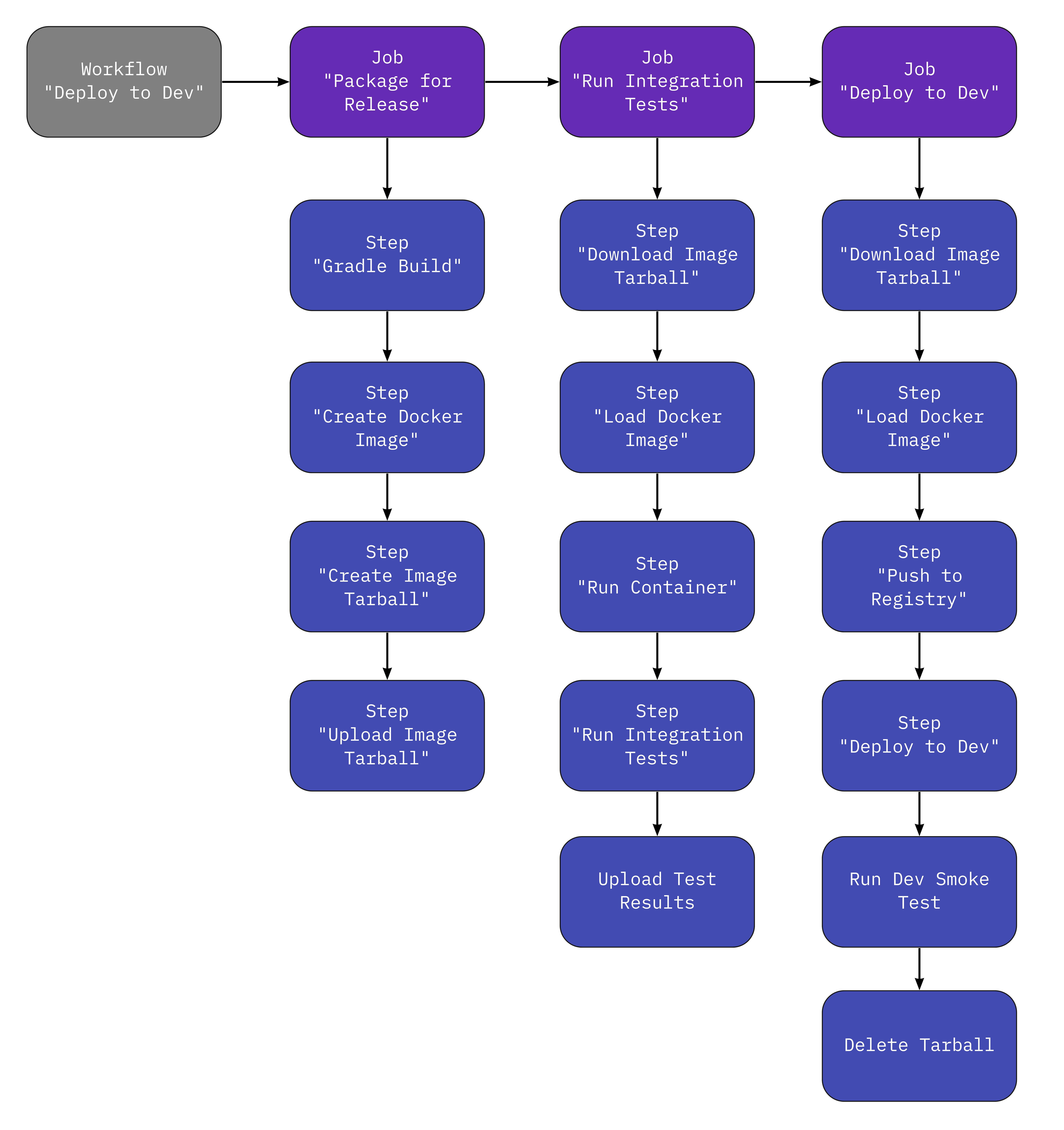
As you can see, A workflow, is a set of jobs (that we run in series or parallel), with each job containing several steps. Jobs describe collections of steps that when together, perform some action that is useful to the business. Model your jobs in terms of things that are useful for you - it’s these aggregates that you’ll be watching most.
Steps are concrete actions that we perform, things like building, unit testing, renaming files and so on. A step is the smallest unit of work you can do in a workflow, and they don’t need to be useful in and of themselves.
The reason I think that jobs should be useful units of work for your business, is because if you plan them that way, it becomes trivial to re-use jobs to achieve new functionality quickly
Pipelines as Code with… YAML
Workflows use YAML as the format of choice, and I YAML in Github Actions as much as I hate any other white spaced language in a place it doesn’t belong. I’m sure Github chose YAML for a good reason, I’ve struggled to find out what those reasons were or are. Work continues in that area.

As with most things that involve YAML, the workflow file is easy to quickly grok while it’s small to medium length but challenging to troubleshoot or do anything with once it gets a bit bigger. Github Actions is still new, so I can understand why it might be a little rough around the edges. Perhaps there is tooling around the workflow file I’m ignorant of, but an equivalent to Bitbucket Pipelines’s pipeline validator would be an excellent addition.
Even better still (and this would be a feature far down the track), give me a fluent API akin to Bamboo's Java Spec Concept .
To save you a click, 90% of my warm fuzzies for Atlassian Bamboo come from being able to do this:
private Plan createPlan() {
return new Plan(
project(),
"Plan Name", "PLANKEY")
.description("Plan created from (enter repository url of your plan)")
.stages(
new Stage("Stage 1")
.jobs(new Job("Build & run", "RUN")
.tasks(
new ScriptTask().inlineBody("echo Hello world!"))));
}
Getting access to this kind of API, and provide auto-completion, intellisense and everything that comes with that ecosystem is war-winning feature for pipeline builders.
I would prefer XML to YAML. There. I said it. We can move on now.
Workflows
What does a workflow file look like? Here’s the file for a Spring Boot application I’m currently working on. I was very focused on getting a minimal workflow up and running, so there are things to be added and things to be optimised.
Have a big read, and I’ll break it down below:
name: Create Release Candidate
on:
push:
branches: [ dev ]
pull_request:
branches: [ dev ]
jobs:
create-rc:
runs-on: ubuntu-latest
steps:
- name: Check out code
uses: actions/checkout@v2
- name: Build and tag release candidate
uses: docker/build-push-action@v1.1.0
with:
username: ${{ secrets.HEROKU_USER }}
password: ${{ secrets.HEROKU_TOKEN }}
registry: registry.heroku.com
repository: image-repository/heroku-process
tags: latest
push: false
- name: Create tarball from docker image
run: docker save registry.heroku.com/image-repository/heroku-process:latest > heroku-process-candidate.tar
- name: Upload image tarball for next job
uses: actions/upload-artifact@v2
with:
name: heroku-process-candidate.tar
path: heroku-process-candidate.tar
integration-test:
runs-on: ubuntu-latest
needs: create-rc
steps:
- name: Check out code
uses: actions/checkout@v2
- name: Download tarball
uses: actions/download-artifact@v2
with:
name: heroku-process-candidate.tar
- name: Load image from tarball
run: docker load < heroku-process-candidate.tar
# github doesn't allow us to gracefully expire artifacts (e.g. keep last 10 build artifacts and no more)
# if we don't delete these, we'll hit the storage limit for actions quickly.
# persisting docker images outside of builds should be done by pushing the image to a registry
# we should rm the tarball as soon as we've loaded it as a docker image.
- name: Tidy up artifact to avoid storage limit
uses: geekyeggo/delete-artifact@v1
with:
name: heroku-process-candidate.tar
- name: Run application server
run: docker run -d -p 8080:8080 -e JAVA_OPTS=-Dspring.profiles.active=dev registry.heroku.com/image-repository/heroku-process:latest
- name: Make server watch script executable
run: chmod +x wait-for-heroku-process.sh
- name: Wait for server to start
run: ./wait-for-heroku-process.sh
- name: Set up JDK 14
uses: actions/setup-java@v1
with:
java-version: 14
- name: Make gradle wrapper executable
run: chmod +x gradlew
- name: Run Integration Tests
run: ./gradlew integrationTest
The above file is just under 100 lines of YAML to describe the first two jobs in the image above (Package for release and Run Integration tests). Now that I’ve finalised everything, it looks pretty clean and tidy, the process to get there was anything but. Again this is something that I’d attribute to new-ness. Still, Github Actions does an excellent job at giving you the low-level details about how a thing works, but a lousy job at describing how you can use what Actions provides you to create higher-order pipelines.
For example, the Gradle starter here does a good job of telling me how to declare jobs, steps and make them dependent on pull requests or branches. It also leaves me with questions. I want to package my application, and then run it, and then only when it’s running, run unit tests. How do I do that? I want to publish to my registry, but only if the unit and integration tests have passed, except for in dev, we can publish there with some failing tests. How do I do that?
The basic building blocks are there, but more complex pipeline logic is missing.
Compare this with the excellent documentation produced by VMWare and Pivotal for Concourse CI that gets much more into higher-order combinations of those basic building blocks.
Compare Gated CI Pipelines and Blue-Green Deployments with Concourse, to anything in the only workflow template repository I could find, Starter Workflows to see that high level / low-level split.
Concourse is a more mature product and more fully-featured, where perhaps Github Actions is still more of a CI tool rather than a CD tool. I’m sure it will get there in time. The portability and reusability that Github Actions provides is a significant advantage over other build tools.
I love how sturdy the modelling and pipelining features are for Concourse. It’s ironic though that at my current workplace we’ve just decided to get off Concourse CI in favour of Github Actions.
Jobs in detail
Here’s the same workflow as above, trimmed for easier reading.
name: Create Release Candidate
on:
push:
branches: [ dev ]
pull_request:
branches: [ dev ]
jobs:
create-rc:
runs-on: ubuntu-latest
steps:
- name: Arbitrary Step 1
run: echo "Hello Muddah"
- name: Arbitrary Step 2
run: echo "Hello Fadduh"
integration-test:
runs-on: ubuntu-latest
needs: create-rc
steps:
- name: Arbitrary Step 1
run: echo "Here I am at"
- name: Arbitrary Step 2
run: echo "Camp Granada."
Important Concepts: Jobs and Steps
- A workflow has one set of jobs
- A job has one set of steps.
- Both of these sets can have one to many items in them. You can have ten jobs, each with 20 steps, or one job with 1 step.
- To create a sequential pipeline, add a
needsstatement in every job after the first one, and in that needs statement, refer to the previous job. For example, I have two jobs,create-rcandintegration-test. In the second job, I have this statement:needs: create-rc. - Importantly, Jobs run in parallel by default. A sequential run like the above is something you have to do specifically. Parallel by default creates advantages if you can decouple your build process.
- Right now, I have to wait for Actions to build my RC and image before I can integration test. I believe in pushing one artefact through the entire pipeline rather than rebuilding it each from source each time - but if I didn’t, I might be able to get super parallelisation on my build pipelines. I.e. rather than Checkout Source > Build > Test > Deploy with one artefact the whole way through, I could Checkout Source > Build, Checkout Source > Test, Checkout Source > Package > Deploy all at the same time. This means the time the build takes is the
max()of the longest job, rather thansum(job_1 + job_2 ... job_n). - I’m an absolute savage though and believe that the best approach is to checkout and built once, and then pass an artefact all the way through. The tradeoff for that certainty is a longer build time (about 5 minutes in this case, but for longer build processes, it probably stacks up quick).
- There is a whole ecosystem of Actions available on the Github Marketplace, but every action you use will cost you in build time. Actions are distributed as Docker images, and when your build runs, before you can build your build, you have to build all of your actions.
- Steps all run sequentially, and an action can be a step, but not all steps have to be actions. For example:
- name: Arbitrary Step 1
run: echo "Hello Mother"
The above is a step that is not an action; the below is a step that is action. All actions are steps, but a step does not have to be an action.
- name: Build and tag release candidate
uses: docker/build-push-action@v1.1.0
with:
username: ${{ secrets.HEROKU_USER }}
password: ${{ secrets.HEROKU_TOKEN }}
registry: registry.heroku.com
repository: image-repository/heroku-process
tags: latest
push: false
Sharing and Storing Artifacts
Each job runs in parallel and runs in a separate container. If you have a job that builds, and you have a job that tests, you have to figure out a way to get the build output into the testing task. Github’s solution to this seems inefficient, but I can’t see any better way of doing it.
Your workflow could happen anywhere, multiple anywhere even. Because jobs are independent, in theory, you could have your build happening over in the US East region and your tests happening in Europe. You can’t rely on them being on the same machine or even in the same DC, so sharing artefacts via cloud storage is the only choice you have.
It gives rise to these two actions:
- name: Upload image tarball for next job
uses: actions/upload-artifact@v2
with:
name: heroku-process-candidate.tar
path: heroku-process-candidate.tar
- name: Download tarball
uses: actions/download-artifact@v2
with:
name: heroku-process-candidate.tar
- name: Load image from tarball
run: docker load < heroku-process-candidate.tar
The way we share artefacts between jobs (or persist them outside of builds) is essentially by uploading and downloading from S3 or an equivalent (I assume they use S3 but haven’t done the research to confirm). I have a small workflow right now, but what this means is that passing my artefact from my first job to the second, accounts for a whopping 21% of the run time of the build. This behaviour pushes me to a perverse outcome where I’m better off starting from scratch in every single job because of the time it takes to trade artefacts! An alternative to that would be to have one enormous job, but that also flies in the face of the whole idea of Github Actions, which is that concept of composable, reusable workflows.
Further, you need to be careful with your usage of artefacts.
On a team or pro plan, you get 2GB of storage for actions. Artefacts associated with builds older than 90 days get deleted. To naturally stay at or under the 2GB limit, your builds need to persist fewer than 22MB per day - not per build, per day worth of artefacts. Github Packages, and storage for Actions, get very spendy, very quickly.
This behaviour gives rise to actions like this one. I consider this 100% required for anybody who has Workflows with more than one job, where you need to pass an artefact between them. Remember, every job that needs to share an artefact will incur the wrath of Github Packages.
# github doesn't allow us to gracefully expire artifacts (e.g. keep last 10 build artifacts and no more)
# if we don't delete these, we'll hit the storage limit for actions quickly.
# persisting docker images outside of builds should be done by pushing the image to a registry
# we should rm the tarball as soon as we've loaded it as a docker image.
- name: Tidy up artifact to avoid storage limit
uses: geekyeggo/delete-artifact@v1
with:
name: heroku-process-candidate.tar
As per the comment, I’d recommend you persist artefacts during builds and between jobs, delete them afterwards, and for audit, viewing test reports and things like that, find somewhere else to put them. Put containers into your registry, put test reports into S3 or similar. For more detail on how this all gets billed, see this
In closing, why use Actions?
I think for a lot of people (myself included), the main draw for Github Actions is that it’s conceptually quite simple (though as with anything there are gotchas), and tightly woven in with Github itself. I like that the build lives close to the code and everything that comes with it. Github Actions is ‘pipeline-as-code’, that isn’t that much of a burden to learn and use, and even having been newly released, it’s as capable as any other build tool I’ve used.
Where it starts to get powerful is the open-source ecosystem of Actions and the tie into wider Github. Be that the code repository or other apps I might have added to my repo or org. I can get this without having to deal with another tool, another login, or the overhead of another new thing. Thinking on it, maybe that’s why they chose YAML.
While I’ve spent a lot of time bagging it, I quite like it. It’s a good example of delivering just enough capability at the right time, and I’m sure Actions will continue to grow, if not via first-party development, certainly through that action ecosystem.
Yes, I’ve got gripes about YAML, but I have that most places I go. You can work around the storage issues, and it’s not unreasonable for Github to try and make money given everything else they provide for free or for cheap. Actions is a fully managed service, no servers to feed and water, no breaking updates so far. With versionable pipelines, there are very few moving parts that we the end-users have to care about. That’s worth more than it’s equivalent weight in gold.
If you’ve got a pet project or something new at work, I recommend you give it a try.